
The Verge's web sucks
TL;DR: Did you know that The Verge delivers you to around 20 companies for advertising & tracking purposes? I didn't. That might foul up your web experience a little bit. Maybe we should try something different.
I love The Verge, but man...
So, I've been a big fan of The Verge, almost since day one. It's a gorgeous site and the content is great.
They've done some amazing things with longform articles like "What's the deal with translating Seinfeld" and "Max Headroom: the definitive history of the 1980s digital icon", and the daily news output is high quality.
But, I have to say, reading Nilay Patel's "The Mobile Web Sucks" felt like getting pelted by rocks thrown from a bright, shiny glass house.
Calling out browser makers for the performance of sites like his? That's a bit much.
Here's my thing: I've never had an iPhone. I've had Palm webOS phones, a parade of Android devices, and now an experimental Boot2Gecko phone on really nice hardware. Some sites have long been a delight on whatever gadget I fetch from my pocket. Others, I've watched decay over the years as their mobile web experiences are neglected in favor of those frantically promoted apps.
The Verge isn't quite either of those. And, for me as a fan, it's frustrating.
Time to open the Dev Tools
A page view on The Verge is a heavy load. I've known this for awhile, but it wasn't until now that I decided to take a peek at what might be wriggling under this log.
So, I opened up the Dev Tools in Firefox and gave the page a reload on a cleared cache.

That's fine - 75kb of HTML for the article. But, I also expect there'll be a font or two and a raft of images.
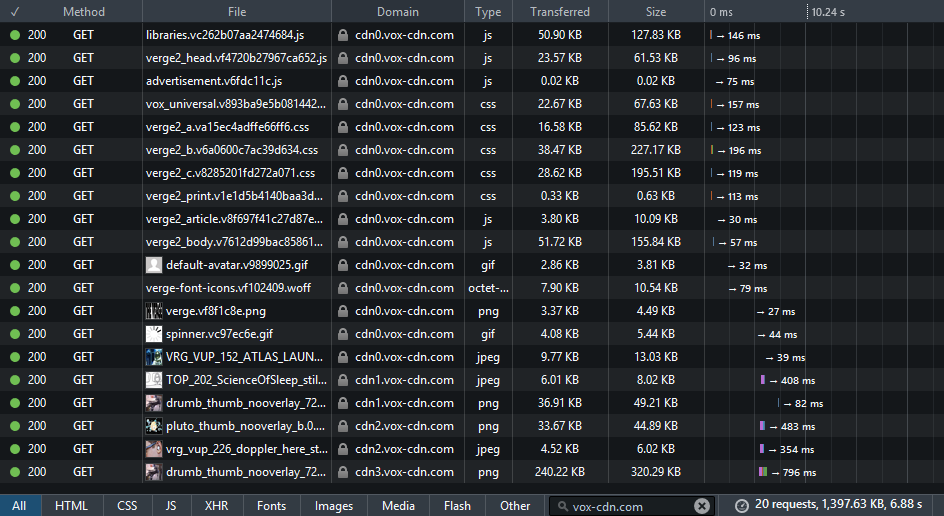
We're up to 20 requests and 1.4MB over ~7 seconds. That's on the upper end of what I'd advise, but it's not terrible. I said that The Verge is a gorgeous site - that takes some resources. Hell, this very blog post is going to be bigger than I'd like thanks to the Twitters & Googles & Disqus, and it's no visual delight either.
Oh, but wait, it's not done loading yet. I'm starting to read & scroll, but my browser's still spinning. I wonder what the final stats will be?
Ow, my data plan!

Holy crap. It took over 30 seconds. In the end, it fetched over 9.5MB across 263 HTTP requests. That's almost an order of magnitude more data & time than needed for the article itself.
What the hell is all this stuff?
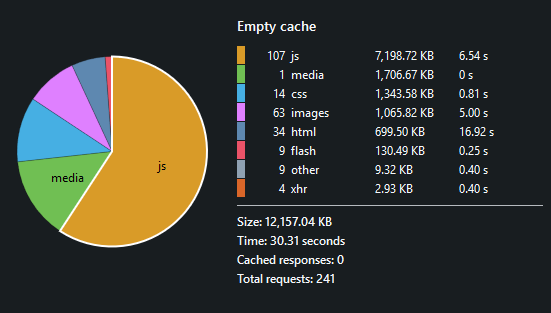
Wow. Devtools performed a second reload of the page to get an overall performance analysis. This time it downloaded 12MB - a little over 7MB in that is JavaScript!
Just to put this in some rough perspective: Assuming I had a 1GB / month data plan, I could visit sites like The Verge about 3 times per day before I hit my cap. If I'm lucky, some or most of this will get cached between requests so it won't be quite that bad. In fact, another report tells me that a primed cache yields 8MB transferred - so maybe 4 visits per day.
That's assuming caches on mobile are comparable to my laptop, which is not a safe assumption.
Still, this isn't one of the cool longform articles on The Verge with interactive features and whatnot. This is just a straightforward 1600 word rant with a few quotes & images. Oh, and one video. Not entirely different than this blog post.
What in the world is all this code doing?
Shining a Lightbeam under the log
Hmm, I think I Nilay Patel tweeted a hint:
@satefan @verge part of the content we deliver is advertising! :)
— nilay patel (@reckless) July 20, 2015Man, I'd hazard a guess that most of what you just delivered was advertising. That, and spyware.
In one of the public Monday update calls at Mozilla I heard about this project called Lightbeam:
Lightbeam is a Firefox add-on that uses interactive visualizations to show you the first and third party sites you interact with on the Web.
So, I figured I'd let it take a look at The Verge. This is what it showed:

Imagine this is an iceberg as viewed from above. The Verge is the tip above water, the big circle in the middle. The triangles dancing around it are third-party sites lurking under the surface. Lightbeam has a list view, so I switched to get a closer look:
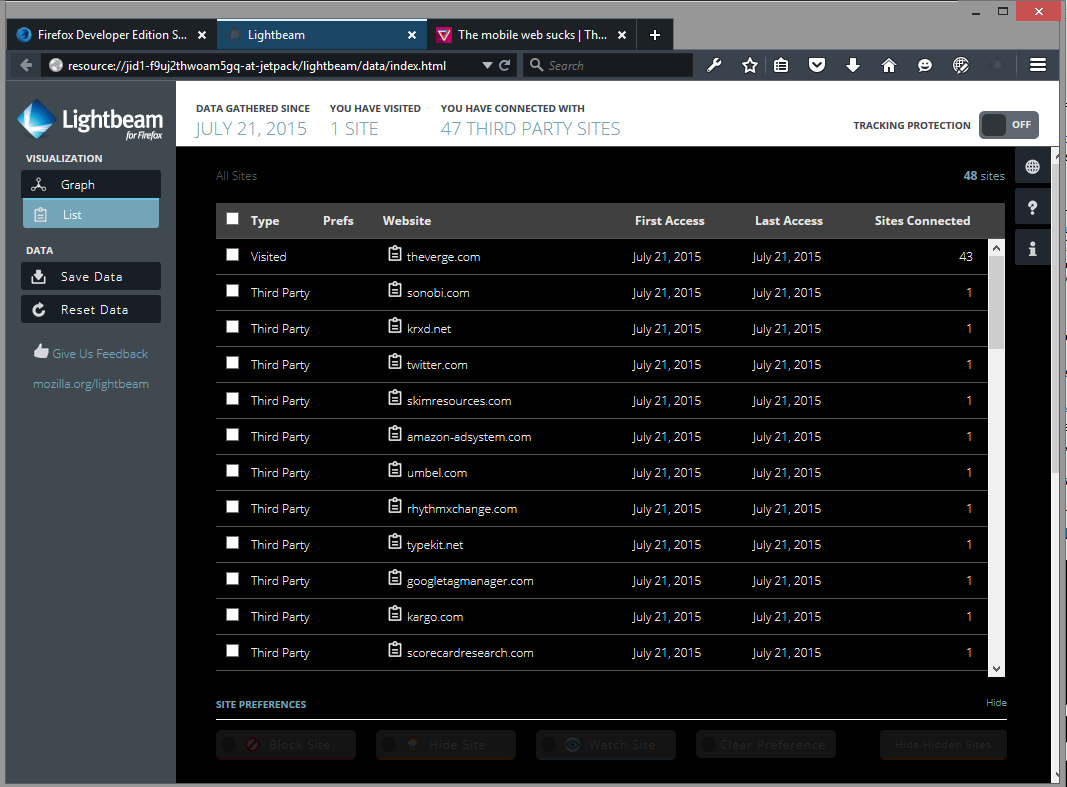
Sweet Jeebus. "You have visited 1 SITE. You have connected with 47 THIRD PARTY SITES."
22 flavors of spyware
Now, to be fair, scrolling through the report I could see that some of these distinct "sites" are clearly alternate domains owned by the same organization. That said, I still found over 20 different companies before I got tired of digging:
- Amazon - "Reach millions of customers who find, discover, and buy at Amazon"
- skimresources.com - "When links in publishers’ content lead their users to click through and buy from an online retailer, we make sure they’re rewarded!"
- sonobi.com - "Sonobi’s suite of buy and sell-side tools allow our customers to identify, deliver, and manage advertising opportunities through performance filters once absent from programmatic channels"
- umbel.com - "Umbel helps you securely collect first-party customer data and combine all of your existing data from multiple sources to give you a complete view of your customers."
- krux.com - "Krux helps businesses drive revenue by delivering smarter content, commerce and marketing experiences to people."
- mediamath.com - "MediaMath’s TerminalOne™ platform activates data, automates execution, and optimizes advertising interactions across addressable media—delivering greater performance, transparency, and control to marketers and a better experience to consumers."
- adnxs.com - "Adnxs™ is a portal for Publishers to the AppNexus® online auction exchange used to sell advertising space."
- bidswitch.net - "BidSwitch provides immediate and seamless real-time access for Supply and Demand Partners across all media types (display, mobile, video, native, etc.)."
- scorecardresearch.com - "ScorecardResearch, a service of Full Circle Studies, Inc., is part of the comScore, Inc. market research community, a leading global market research effort that studies and reports on Internet trends and behavior."
- kargo.com - "Kargo weaves our content and ad technology into our premium publishers’ mobile and tablet properties, offering advertisers the best brand experiences."
- quantcast.com - "Understand your audience. Find your next customer."
- moatads.com - "Moat's proprietary ad search engine has become a ubiquitous tool for the display ad industry. Moat makes it easy to find what and where ads are running for the top brands and sites."
- flashtalking.com - "Flashtalking is an independent ad serving, measuring and technology company, providing best-in-class digital advertising products, service and support for online advertisers, key media buying and creative agencies."
- lotame.com - "Lotame is a data management platform (DMP) that lets marketers, agencies and publishers harness audience data to make smarter marketing, product and business decisions."
- ixicorp.com - "IXI Services enables its clients to differentiate and target consumer households and target markets based on proprietary measures of wealth, income, spending capacity, credit, share-of-wallet, and share-of-market."
- chartbeat.com - "We partner with editorial teams to identify their highest quality content -- the pieces that pique and keep reader attention. We partner with advertising teams to plan campaigns around this high-quality content so these ads are seen more often and for longer."
- bombora.com - "We are the largest aggregator of B2B intent driven data."
- taboola.com - "Taboola recommends editorial and sponsored content across many of the world’s most highly-trafficked sites."
- bluekai.com - "BlueKai is the industry's leading cloud-based big data platform that enables companies to personalize online, offline and mobile marketing campaigns with richer and more actionable information about targeted audiences."
- marketo.com - "Marketo has developed the industry’s leading engagement marketing platform, the broadest ecosystem of partners, and the deepest expertise to make this all possible."
- retargeter.com - "ReTargeter optimizes your ad spend with highly targeted, real time digital advertising solutions and the best account management in the industry."
Make time to visit the vendor hall!
I feel like someone just set up the entire vendor hall from an awful tech conference in my living room. Seriously, could you folks just not pick one or two or ten? Did you hit every booth and say "Yeah, cool, sign us up!" I feel thoroughly spindled & folded & researched, here.
As a webdev at Mozilla, I've been in hour-long meetings where we've agonized over whether it's copacetic to include just one little Google Analytics snippet without notifying users and updating the privacy policy. But, I know we're crazy in our own very special ways.
In former lives, I've worked at ad agencies and digital marketing companies. I'm no stranger to conversations that revolve around partners & bizdev & analytics & media buys. I can only imagine things have intensified & evolved since I've been out of those trenches.
Still - and maybe this is the Mozilla brain-damage talking - I can't imagine a sane conversation that resulted in The Verge extending an invitation to over 20 companies to set up shop on my computer with every page visit. I can only imagine this as a steady drip-drop of bizdev decisions and emails to internal webdevs:
"Hey, can you add this tracking pixel? These guys do realtime attention heatmapping and it's brilliant!"
"Paste this snippet into the global template, please? This fourth programmatic ad platform is really going to fill in the gaps for the other three."
"One more script thing here. We need to capture the affiliate credit for all these links going out to e-commerce sites."
"Oh hey, we're going to need this new script to manage the dozen ad platforms we use now."
I'm guessing no one along the way had the power or motivation to say no. I mean, really, what's the cost in tossing one more straw onto that camel's back? I know I never looked or complained until now, and I doubt the majority of readers will ever bother.
We all just kind of get this growing sense of malaise about "the web" as a gestalt of our favorite sites as they get suckier.
How to make the web suck
So, I haven't taken the time to dig into the source code of those companies' specific contributions to the article. There are only so many hours in the day, and I have a ranty blog post to finish.
But, if you want to talk about browser performance - mobile or desktop - don't you think that maybe, just maybe, some of that 7 megabytes of JavaScript code might have an impact?
First, even assuming this code comes from a local cache, parsing it into something executable has a cost. Of course, someday, we'll have WebAssembly to shift this first stage upstream into webdev build tools. But we don't have that, yet.
Then, there's what that code's actually doing once it runs. There's the usual reporting on every scrap of browser fingerprint data. There's deciding whether and what ads to fetch & inject. I've seen scripts that record every pixel of mouse movement and phone home every few seconds.
Some spawn lots of hidden iframes, each doing something fun. Others run code 10 times per second that trigger little invisible page re-renderings that chew up CPU and make scrolling & orientation changes chug. Some scripts get run multiple times and perform duplicate work. Attack ships on fire off the shoulder of Orion. I watched C-beams glitter in the dark near the Tannhauser gate.
Wait, where was I?
Everybody's (not) doing it!
I've seen the argument that this is how the web gets funded. Everybody's doing it. This is the current state of the art. Browsers just need to suck it up & make it happen.
Some sites are (much) better than others, though, and it doesn't seem to be directly related to the content. Here's what I saw when I did a quick check of some daily reads:
 - Forbes
- Forbes - The Huffington Post
- The Huffington Post - CNN
- CNN - Readwrite
- Readwrite - BBC
- BBC - Ars Technica
- Ars Technica - Quartz
- Quartz - NPR
- NPR - io9
- io9 - The Guardian
- The Guardian - Mozilla
- Mozilla - Mozilla Developer Network
- Mozilla Developer Network
If you've bought into my thesis that this stuff should take a lot of the blame for poor mobile performance - it's no surprise that I'll claim these sites are progressively better experiences as I step down the list.
I also didn't dig deeply into each of these. But, it's pretty clear The Verge blows other sites out of the water in terms of what it demands from a browser. Forbes is a very close second, though, and it sometimes seems to do annoying things like phone home every second or so while I'm on the page.
Oh, and admittedly I don't visit the Mozilla home page as a "daily read", though I do use MDN regularly. I've also worked on both, so I have some notion of what they're (not) doing - and how much we beat ourselves up internally about reaching sub-second page loads. (Man, do we look good now, or what?)
What are browsers for, anyway?
Nilay Patel says "what we really need is a more powerful, more robust web." Personally, I think the web we have right now can be pretty damn powerful & robust. Stop trying to make a sedan tow a house.
But, is it ultimately a good idea to optimize for these icebergs that consist of the tiny bit we came for, perched atop a great big submerged intelligence gathering apparatus assembled on-demand from a consortium of marketing & analytics firms?
Just what are we building these browsers for? Is this what we want as users? Because, browsers are user agents. I know the web needs to get funded, somehow. But should the agents operating on our behalf just blindly accept whatever publishers want to send gurgling down the pipes? Maybe our agents should be asserting themselves to get us a better deal & better performance. This is dangerous talk, I know, and it implies some slippery slopes.
Apropos of that, it could be worse: Consider things like Flipboard, Facebook's Instant Articles, and Apple's News app. These are highly assertive agents that offer great reading experiences.
In a nutshell, they do it by making publishers less free to crap it all up and users less free to encounter crap. That is, "curation". As gatekeepers, they force publishers to strip it all down and make their deals with just one middle man. Win-win - except it's a solution for a self-made problem that introduces new gatekeepers and leaves us with far less choice & control over our agents.
Maybe paying for the web can be better?
Browsers have typically tried to stay neutral, because asserting an opinion can start some nasty fights. But, if the choice is to watch the web head off into the sunset, what do we have to lose? Maybe browsers should impose a few of the constraints these news apps introduce. We keep things like Adblock Plus at arm's length for plausible deniability - but everyone I know uses it.
Meanwhile, there are people pondering how to improve funding for the web. Believe it or not, the Content Services team at Mozilla is thinking about way more than just "plunking ads into Firefox". Like, what if we actually accepted the fact that ads are a way of funding the web at large, and browsers themselves offered built-in mechanisms to support advertising that respect privacy & performance? Yeah, that's a bit of a change from browsers' traditional neutrality. But, it could be a better deal for publishers and users together.
Here's another idea: Almost a year ago, I heard the notion of "Subscribe 2 Web" at Mozilla. The gist is that you're worth about $6.20 per month across publishers via advertising revenues. What if you paid that much into an account yourself every month and used a mechanism built into your browser to distribute that money? Yeah, it's micropayments, but I find it interesting that these folks came up with a specific dollar amount that doesn't sound terrible.
But, if you don't like that, we have other options. I'm a listener of Tom Merritt's Daily Tech News Show - and I support him via Patreon. We've also got things like Flattr. We've got a pile of other ideas out there - but, none of them are as convenient as web spyware when users don't complain or impose a cost. If browsers started getting tough on web spyware, necessity might force some of these options to grow.
Wrapping up
So, I'm out of steam. Sorry (not sorry) for the wall of text, and the complete lack of pictures toward the end.
Anyway, yeah, there are many things that can make the mobile web suck. Bad CSS layout, heavy UI frameworks, you name it. And, yeah, browsers can get better. They are getting better. There are interesting capabilities on the horizon.
But, I can't help thinking if everyone shrank those tracking & advertising icebergs down to some sane magnitude relative to the actual content, that this web might be a better place overall.